


에이전트 훈련시키기¶
이 페이지에서는 Gymnasium 환경에서 에이전트를 훈련시키는 방법에 대한 간략한 개요를 제공합니다. 특히, 테이블 기반 Q-learning을 사용하여 Blackjack v1 환경을 해결할 것입니다. 이 튜토리얼의 전체 버전과 다른 환경 및 알고리즘에 대한 더 많은 훈련 튜토리얼은 이곳을 참조하십시오. 이 페이지를 읽기 전에 기본 사용법을 읽어보시기 바랍니다. 코드를 구현하기 전에 Blackjack 및 Q-learning에 대한 개요를 살펴보겠습니다.
Blackjack은 특정 조건에서 이길 수 있다는 악명 높은 가장 인기 있는 카지노 카드 게임 중 하나입니다. 이 버전의 게임은 무한 덱(카드를 대체하여 뽑습니다)을 사용하므로, 카드 카운팅은 시뮬레이션 게임에서 실행 가능한 전략이 되지 않습니다. 관찰값은 플레이어의 현재 합계, 딜러의 앞면 카드 값, 그리고 플레이어가 사용 가능한 에이스를 가지고 있는지 여부에 대한 부울 값으로 구성된 튜플입니다. 에이전트는 두 가지 행동 중 하나를 선택할 수 있습니다: 스탠드(0)는 플레이어가 더 이상 카드를 받지 않는 것이고, 히트(1)는 플레이어가 카드를 한 장 더 받는 것입니다. 이기려면 카드 합계가 딜러보다 크고 21을 초과하지 않아야 합니다. 플레이어가 스탠드를 선택하거나 카드 합계가 21보다 커지면 게임이 종료됩니다. 전체 문서는 https://gymnasium.farama.org/environments/toy_text/blackjack에서 찾을 수 있습니다.
Q-learning은 Watkins, 1989년에 의해 개발된 이산 액션 공간을 가진 환경을 위한 모델 프리 오프-폴리시 학습 알고리즘이며, 특정 조건 하에서 최적 정책으로 수렴함을 증명한 최초의 강화 학습 알고리즘으로 유명합니다.
액션 실행하기¶
첫 번째 관찰을 받은 후에는 환경과 상호작용하기 위해 env.step(action) 함수만 사용할 것입니다. 이 함수는 액션을 입력으로 받아 환경에서 실행합니다. 이 액션이 환경의 상태를 변경하기 때문에 네 가지 유용한 변수를 반환합니다. 이들은 다음과 같습니다:
next observation: 에이전트가 액션을 취한 후 받게 될 관찰입니다.reward: 에이전트가 액션을 취한 후 받게 될 보상입니다.terminated: 환경이 종료되었는지(내부 조건으로 인해 종료되었는지) 여부를 나타내는 부울 변수입니다.truncated: 에피소드가 조기 단축으로 종료되었는지(예: 시간 제한에 도달했는지) 여부를 나타내는 부울 변수입니다.info: 환경에 대한 추가 정보를 포함할 수 있는 사전입니다.
next observation, reward, terminated, truncated 변수는 자명하지만, info 변수는 추가 설명이 필요합니다. 이 변수에는 환경에 대한 추가 정보가 포함될 수 있는 사전이 포함되어 있지만, Blackjack-v1 환경에서는 무시할 수 있습니다. 예를 들어 Atari 환경에서는 info 사전에 ale.lives 키가 있어 에이전트의 남은 생명 수를 알려줍니다. 에이전트의 생명이 0이면 에피소드는 종료됩니다.
env.render()를 훈련 루프에서 호출하는 것은 훈련 속도를 매우 늦추기 때문에 좋지 않습니다. 대신 훈련 후에 에이전트를 평가하고 보여주기 위한 별도의 루프를 만드는 것이 좋습니다.
에이전트 구축하기¶
Blackjack을 해결할 Q-learning 에이전트를 만들어 봅시다! 액션을 선택하고 에이전트의 액션 값을 업데이트하기 위한 몇 가지 함수가 필요할 것입니다. 에이전트가 환경을 탐색하도록 보장하기 위한 한 가지 가능한 해결책은 엡실론-탐욕 전략입니다. 이 전략에서는 epsilon 확률로 무작위 액션을 선택하고, 1 - epsilon 확률로 탐욕적인 액션(현재 가장 좋은 것으로 평가된 액션)을 선택합니다.
from collections import defaultdict
import gymnasium as gym
import numpy as np
class BlackjackAgent:
def __init__(
self,
env: gym.Env,
learning_rate: float,
initial_epsilon: float,
epsilon_decay: float,
final_epsilon: float,
discount_factor: float = 0.95,
):
"""Initialize a Reinforcement Learning agent with an empty dictionary
of state-action values (q_values), a learning rate and an epsilon.
Args:
env: The training environment
learning_rate: The learning rate
initial_epsilon: The initial epsilon value
epsilon_decay: The decay for epsilon
final_epsilon: The final epsilon value
discount_factor: The discount factor for computing the Q-value
"""
self.env = env
self.q_values = defaultdict(lambda: np.zeros(env.action_space.n))
self.lr = learning_rate
self.discount_factor = discount_factor
self.epsilon = initial_epsilon
self.epsilon_decay = epsilon_decay
self.final_epsilon = final_epsilon
self.training_error = []
def get_action(self, obs: tuple[int, int, bool]) -> int:
"""
Returns the best action with probability (1 - epsilon)
otherwise a random action with probability epsilon to ensure exploration.
"""
# with probability epsilon return a random action to explore the environment
if np.random.random() < self.epsilon:
return self.env.action_space.sample()
# with probability (1 - epsilon) act greedily (exploit)
else:
return int(np.argmax(self.q_values[obs]))
def update(
self,
obs: tuple[int, int, bool],
action: int,
reward: float,
terminated: bool,
next_obs: tuple[int, int, bool],
):
"""Updates the Q-value of an action."""
future_q_value = (not terminated) * np.max(self.q_values[next_obs])
temporal_difference = (
reward + self.discount_factor * future_q_value - self.q_values[obs][action]
)
self.q_values[obs][action] = (
self.q_values[obs][action] + self.lr * temporal_difference
)
self.training_error.append(temporal_difference)
def decay_epsilon(self):
self.epsilon = max(self.final_epsilon, self.epsilon - self.epsilon_decay)
에이전트 훈련시키기¶
에이전트를 훈련시키기 위해, 에이전트가 한 번에 하나의 에피소드(한 번의 완전한 게임을 에피소드라고 합니다)를 플레이하도록 하고 에피소드 동안 취한 각 액션 후에 Q-값을 업데이트할 것입니다. 에이전트는 환경을 충분히 탐색하기 위해 많은 에피소드를 경험해야 합니다.
# hyperparameters
learning_rate = 0.01
n_episodes = 100_000
start_epsilon = 1.0
epsilon_decay = start_epsilon / (n_episodes / 2) # reduce the exploration over time
final_epsilon = 0.1
env = gym.make("Blackjack-v1", sab=False)
env = gym.wrappers.RecordEpisodeStatistics(env, buffer_length=n_episodes)
agent = BlackjackAgent(
env=env,
learning_rate=learning_rate,
initial_epsilon=start_epsilon,
epsilon_decay=epsilon_decay,
final_epsilon=final_epsilon,
)
정보: 현재 하이퍼파라미터는 적절한 에이전트를 빠르게 훈련시키도록 설정되어 있습니다. 최적 정책으로 수렴하려면 n_episodes를 10배 늘리고 learning_rate를 낮춰보세요 (예: 0.001로).
from tqdm import tqdm
for episode in tqdm(range(n_episodes)):
obs, info = env.reset()
done = False
# play one episode
while not done:
action = agent.get_action(obs)
next_obs, reward, terminated, truncated, info = env.step(action)
# update the agent
agent.update(obs, action, reward, terminated, next_obs)
# update if the environment is done and the current obs
done = terminated or truncated
obs = next_obs
agent.decay_epsilon()
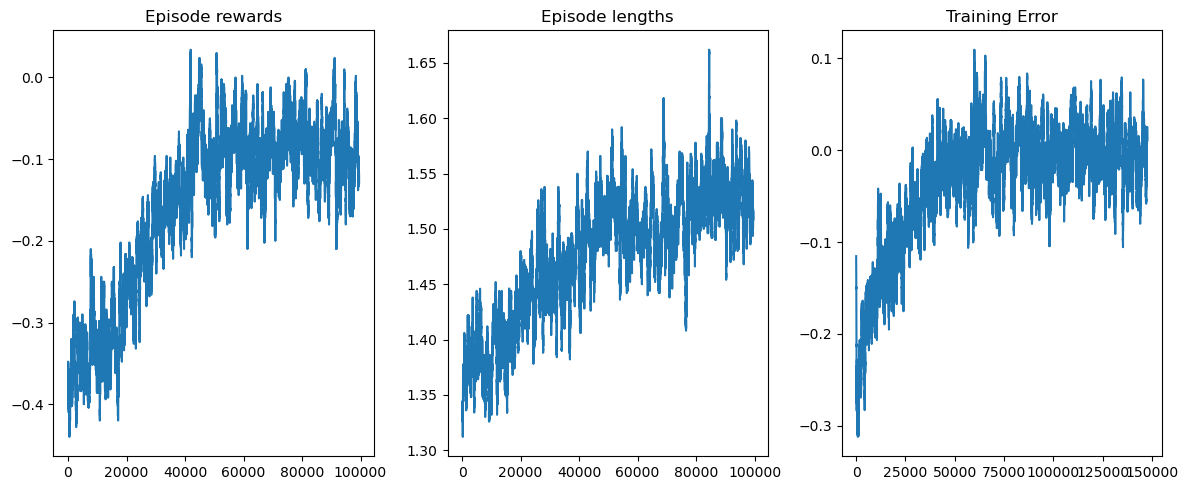
matplotlib을 사용하여 훈련 보상과 길이를 시각화할 수 있습니다.
from matplotlib import pyplot as plt
def get_moving_avgs(arr, window, convolution_mode):
return np.convolve(
np.array(arr).flatten(),
np.ones(window),
mode=convolution_mode
) / window
# Smooth over a 500 episode window
rolling_length = 500
fig, axs = plt.subplots(ncols=3, figsize=(12, 5))
axs[0].set_title("Episode rewards")
reward_moving_average = get_moving_avgs(
env.return_queue,
rolling_length,
"valid"
)
axs[0].plot(range(len(reward_moving_average)), reward_moving_average)
axs[1].set_title("Episode lengths")
length_moving_average = get_moving_avgs(
env.length_queue,
rolling_length,
"valid"
)
axs[1].plot(range(len(length_moving_average)), length_moving_average)
axs[2].set_title("Training Error")
training_error_moving_average = get_moving_avgs(
agent.training_error,
rolling_length,
"same"
)
axs[2].plot(range(len(training_error_moving_average)), training_error_moving_average)
plt.tight_layout()
plt.show()
이 튜토리얼이 Gymnasium 환경과 상호작용하는 방법에 대해 이해하고 더 많은 RL 문제를 해결하는 여정을 시작하는 데 도움이 되었기를 바랍니다.
이 환경을 직접 해결해 보시는 것을 권장합니다 (프로젝트 기반 학습이 정말 효과적입니다!). 좋아하는 이산 RL 알고리즘을 적용하거나 Monte Carlo ES를 시도해 볼 수 있습니다 (Sutton & Barto <http://incompleteideas.net/book/the-book-2nd.html>_의 5.3절에 설명되어 있습니다) - 이렇게 하면 결과를 책과 직접 비교할 수 있습니다.
행운을 빕니다!